I recently came across a bug with SQL Server and Availability Groups whereby catalog view data is incorrectly reported on all secondary replicas.
This bug has the potential for putting the availability of your environment at risk as reporting around capacity could be calculated incorrectly.
Very similar to an old bug with mirroring in SQL Server 2008 R2 this issue affects the sys.master_files catalog view. In this view you can see information around the names, sizes, growths, and locations of all of the files on all of the databases in your server. This bug, when encountered, leaves the information in sys.master_files on an Availability Group secondary replica in an inaccurate state when filegrowth settings are changed on the primary replica.
Let’s take a local lab example (SQL Server 2014)
I have an AG which contains the AdventureWorks2014 database. There is a primary, and two secondary replicas. By using a server groups in SSMS I can query each of them from a single command to capture file information.
Here I am pulling the data from sys.master_files, and AdventureWorks.sys.database_files. Both views return the same (correct) information:

After running a script on the AG primary replica to change the filegrowth settings on the data, and the log file, I would expect to see this information reflected in all locations.
ALTER DATABASE AdventureWorks2014 MODIFY FILE (NAME = AdventureWorks2014_Log, FILEGROWTH = 100MB); ALTER DATABASE AdventureWorks2014 MODIFY FILE (NAME = AdventureWorks2014_Data, FILEGROWTH = 200MB);
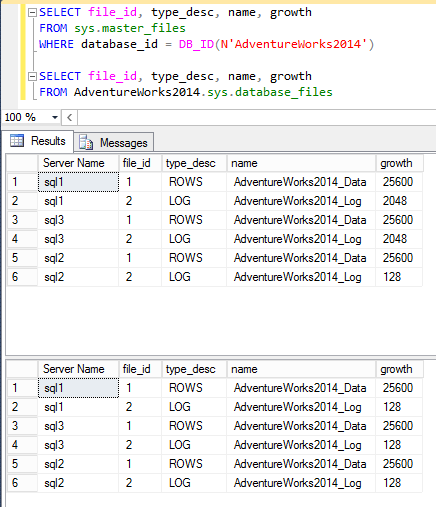
As you can see sys.database_files correctly reflects the changes on all servers. In sys.master_files the data file change is correctly set, however, the log file change is only accurate on the primary replica.
If you happen to be reporting disk usage, and forecasting how database file growth could impact your available storage then you could be using bad data to figure things out.
There is a workaround for this, that is to restart the secondary replicas, at which point they will pick up the change, but until then they’ll be wrong. Note, that even after failing over the primary to a secondary the information will be incorrect in sys.master_files until you make another change, or restart the service.
I’ve filed a bug on Microsoft Connect (sys.master_files catalog view for TLOG growth is not updated on an AG secondary) in the hopes that this can get resolved. Please go and upvote if you also have this issue.
Currently I’ve been able to repo on 2012, and 2014. Testing on 2016 CTP 3.0 to come.

I think you might find another similar bug at least in SQL2012 SP2 builds but has been there for some time. We set alerts for database expansion so that when the datafiles expand we know. In an AG our re-indexing will cause a database to expand but the alert only fires on the primary replica. As soon as the AG fails over the alert will fire on the other replica. This makes me think for what you found that maybe the sys.master_files info is not being updated on the secondary just like you found.
Chris
LikeLike
I’ve not seen this behavior happen with data files (and have tested on SQL 2012 SP2) which makes me wonder if something else is happening. What method are you using to set the alert? If, for example, it is monitoring the default trace, then it’s possible that no entries are written there until such time as the database is a primary. I’ve not looked into that scenario.
LikeLike
It’s a simple SQL Server performance condition alert, SQLServer:Databases, Data File(s) Size (KB).
Chris
LikeLike
Interesting. Take a look at the data in the default trace, see when the growth gets written. Either than or performance conditions ignore databases that are in a recovering state.
LikeLike
I cannot see any event in the default trace for a database expansion. I had a database expand earlier today and the primary replica fired the alert but of course the secondary didn’t.
Chris
LikeLike