Quick, what’s the fastest and easiest way to get data out of a SQL Server table?
Time’s up. It’s BCP.
If you aren’t familiar with BCP it is a command line utility to bulk copy data out of, and in to tables. It has been around for donkeys years (technical term), and while it doesn’t have the frills of SSIS it is fast, and lightweight. DBAs have been using it for years, but it may not be something that you’ve heard of.
Recently, while BCPing some data between servers I ran into an interesting problem which caused the data imported to be different than that exported. How does that happen? Code pages…
What is a code page?
A code page is a method of encoding a character set. There are many different code pages, but you are probably most familiar (if you work with SQL Server in the US) with code page 1252. This is the code page that SQL uses with the default install and collation settings, you may know it as SQL_Latin1_General_CP1_CI_AS.
Installation collation breakdown
- SQL_Latin1_General – The language to which the sorting rules are applied
- CP1 – Code page (CP1 = 1252)
- CI – Case sensitivity, in this case Case Insensitive
- AS – Accent Sensitivity, in this case Accent Sensitive
TechNet and the SQL Server documentation have a list of all the potential installation collations.
Using BCP
There are many arguments that can be used to adjust the way that BCP functions, certainly more than I could scope in this post. However there are a couple of very basic commands that you can use to get data out and in…
bcp <Database.Schema.Table> out <FileName> -n -T -S localhost
Let’s break this down
- bcp – the executable
- Database.Schema.Table – the object containing the data you want to export
- out – the direction in which the data is going
- filename – the file name (including path) for the data
- -n – does the bulk copy using the native database data types
- -T – use integrated authentication
- -S – the SQL instance to connect to, in this case localhost
This will export the data to a native file (that won’t be easily readable in a text editor). It will be very efficient at doing what it does, and should give us the right result.
Let’s test this.
Export and Import Some Data
First we need to setup a couple of tables, and load a few rows of data so that we have something to work with.
CREATE TABLE CodePageTests ( RowID INT NOT NULL, TestString VARCHAR(100) NOT NULL ) GO CREATE TABLE ImportCodePageTests ( RowID INT NOT NULL, TestString VARCHAR(100) NOT NULL ) GO INSERT INTO CodePageTests (RowID, TestString) VALUES (1, 'Copyright ©') , (2, 'GBP £') , (3, 'Registered Trademark ®') , (4, 'Eszett (S Sharp) ß') GO

Now we’ll bcp the data out of the CodePageTests table in to a native file.

And bcp it back in to the import table
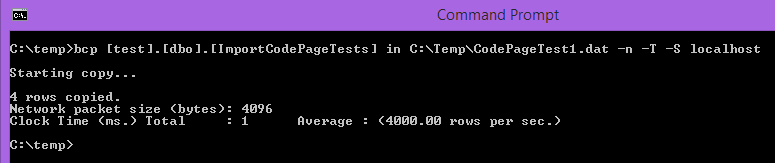
Now if we query the data we’ll see something isn’t quite right…
SELECT c.RowID, c.TestString, i.TestString AS ImportedString FROM CodePageTests c JOIN ImportCodePageTests i ON c.RowID = i.RowID
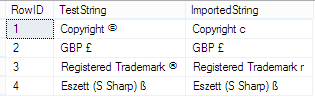
The copyright and trademark symbols have been changed to regular characters, even though the British Pound and Eszett symbols haven’t.
Why is this happening?
The reason this issue crops up is because of the code page that is used during the export (and the import) process.
When using the -n argument bcp will use the native data types. In this instance the © and ® characters will be read as a varchar type. You would, naturally, expect these to be exported and imported. The trouble is that bcp, instead of using the code page of the database, uses (unless otherwise specified) the code page currently set in the software that makes the call.
Here we are instantiating bcp from a command line window in a standard US configuration of Windows. As such the code page defaults to 437. You can check this by executing chcp at the command line:

If you do a comparison of the database code page of 1252, and the Windows one of 437 then you’ll see that a completely different set of characters is supported, and this is where things go off the rails.
How can this be fixed?
There are a few different options you can use to get the data out and in accurately.
Change the code page in the command window before calling bcp
By entering the code page you want to use after the chcp command you can change the default code page used in the command line window (this works just for this window and session, it does not make a permanent change). Then you can call bcp, and the data will be handled correctly.

Change the bcp command to include a code page reference
You can include the -C argument along with the number of the code page you want to use, or, if you know it is a default database install you can use ACP which is the reference to Windows code page 1252

Force bcp to use Unicode storage for certain data
By passing along the -N argument instead of -n you can have bcp examine the data and use a unicode format for character data. Using two-bytes of storage ensures that the data is accurately read and written (although it can cause problems with non-variable length character columns).
Use a format file
A format file has a large advantage as it specifies the data type and collation for each of the columns that you would be exporting or importing. You can generate xml files manually for this, or let bcp do the heavy lifting for you.

You can then use the format file in the bcp process.

Getting the data back in
To bcp the data back in again use the same method that you did for exporting it
- Change the code page for the Window
- Specify a code page in the bcp command
- Use unicode storage for character data
- Use a format file

Then you should be able to query the data and get the right results
SELECT c.RowID, c.TestString, i.TestString AS ImportedString FROM CodePageTests c JOIN ImportCodePageTests i ON c.RowID = i.RowID

TL;DR
While bcp is a great little executable for getting data in and out of SQL Server you have to be careful with how you use it in order to ensure that the data you are exporting and importing is accurate.
For lots more detail read all about the bcp utility on MSDN.

Good . excellent. Marvelous
LikeLike